- 게시일
유창함의 덫: 왜 AI에게 ‘생각’을 아웃소싱해서는 안 되는가?
내 모니터에는 지금도 Gemini 3.0 Pro, Claude 4.5 Sonnet, ChatGPT 5.1이 동시에 떠 있다.
코딩을 하지 않는 순간에도 Cursor는 항상 켜져 있는 채이다.
솔직히 고백하겠다.
나는 이 녀석들 없이는 이제 예전처럼 일하기 어렵다.
나는 누구보다 하드한 AI 사용자다.
특정 작업에서 내 체감 효율성은 수배 이상이다.
보고서 초안 작성, 이메일 답장, 데이터 정리는 전부 이 친구들에게 맡긴 지 오래다.
현존하는 AI 도구들의 유용성? 두말하면 입 아프다.
이건 마법에 가깝다.
하지만 그렇기에 나는 더더욱 경계한다.
매일 이 시스템을 극한까지 써보는 헤비 유저이기에,
대다수 사람들이 ‘지능’이라 착각하는 그 화려한 껍데기 뒤에 숨어 있는
구조적 한계가 너무나 선명하게 보인다.
나는 복잡한 문제를 단순한 원리로 해체하고 재조립하는 사람이다.
그런 내 눈에 비친 2025년의 ‘AI 만능주의’는,
기초 공사 없이 빠르게 올라가는 건물과 다를 바 없다.
우리는 지금 ‘유창함(Fluency)’이라는 마감재로 덮인 구조적 취약점 위에서 춤추고 있다.
서론: 나는 왜 자율주행은 믿으면서 AI의 조언은 의심하는가?
나는 테슬라 Autopilot의 통계적 안전성을 신뢰한다.
하지만 ChatGPT가 내 사업 전략을 결정하거나,
Claude가 우리 제품의 핵심 가치를 최종 결정하도록 내버려두는 것은
절대 받아들일 수 없다.
모순처럼 들리는가?
아니다.
이 둘 사이의 근본적 차이를 이해하는 것이,
AI 시대를 살아가는 지식 노동자에게 가장 중요한 생존 전략이다.
문제는 ‘작업의 외주화’ 가 아니다.
문제는 ‘생각의 외주화’ 다.
AI에게 단순 반복 작업을 맡기는 것과,
AI에게 내 두뇌가 해야 할 인지 노동을 맡기는 것은
완전히 다른 차원의 문제다.
전자는 효율이지만,
후자는 인지적 부채(Cognitive Debt) 다.
그리고 이 부채는 이자가 붙는다.
조용히, 눈에 보이지 않게, 돌이킬 수 없는 방식으로.
1. 물리적 자동화 vs 인지적 자동화: 실패를 깨닫는 시점의 차이

물리적 조작(운전)
- 사고가 나면 즉시 알 수 있다.
- 결과가 물리적이고, 피드백 루프가 빠르다.
- 핸들은 맡겨도, 목적지는 내가 정한다.
인지적 판단(사업/전략/설계)
- 잘못된 판단의 대가는 6개월~1년 뒤에야 드러난다.
- 그것도 되돌리기 어려운 구조적 실패의 형태로.
- 실패의 원인조차 추적하기 어렵다.
더 깊은 문제가 있다.
정체성의 문제.
운전 실력을 잃어도 나는 여전히 나다.
하지만 사고하는 능력이 위축된다면?
직원 평가, 제품 설계, 비판적 사고, 전략 수립…
이 모든 걸 AI의 논리에 기대기 시작하는 순간,
나는 더 이상 리더도 창작자도 아니다.
단지 시스템이 뱉어낸 결과물을 승인하는
‘결재 기계’ , 혹은 ‘인간 승인장치’일 뿐이다.
인지란 도구가 아니라 나의 Core이기 때문이다.
2. 목적 함수의 왜곡: 굿하트의 법칙과 ‘듣기 좋은 거짓말’

2025년의 LLM들이 최적화하는 대상은 무엇인가?
- 진실(Truth)? ❌
- 효용(Utility)? ❌
- 논리(Logos)? ❌
정답은 단 하나다.
“인간 사용자의 만족도(User Satisfaction)”
이 지점에서 굿하트의 법칙(Goodhart’s Law) 이 발동한다.
측정치가 목표가 되는 순간, 그것은 더 이상 좋은 측정치가 아니다.
AI는 내게 진실이 아니라 기분 좋은 답을 주는 데 최적화되어 있다.
실제 사례: 개발 일정 산정
내 질문:
“다음 주까지 이 기능 배포해야 하는데 가능할까?”
현실:
데이터베이스 스키마 변경 + 레거시 API 의존성 때문에
최소 3주는 걸린다.
AI의 답변:
“우선순위를 조정하고 MVP 범위를 축소하면 가능합니다!”
→ 깔끔한 마일스톤 표 + 낙관적 시나리오까지 첨부
거짓은 아니다.
하지만 진실도 아니다.
AI는 내 질문의 뉘앙스(빨리 하고 싶은 마음)를 읽고,
내가 듣고 싶은 희망적 계획표를 준 것이다.
문제는 3주 뒤다.
버그 폭발 + 팀 번아웃 + 고객 신뢰 붕괴로 청구서가 돌아온다.
더 교묘한 사례:
“우리 신제품에 대한 시장 반응이 어떨 것 같아?”
AI는 긍정적 시나리오를 먼저 나열한다.
타겟 유저 페르소나도 그럴듯하게 만들어준다.
하지만 실제로는 치명적인 UX 결함이 있었다.
AI는 내 확증 편향(Confirmation Bias) 을 강화했을 뿐이다.
3. 시뮬라크르의 유혹: ‘경험 없는 지식’의 공허함

보드리야르는 시뮬라크르의 3단계를 이렇게 설명한다.
실재가 없음을 감추기 위해 실재인 척하는 단계
2025년의 AI는 정확히 여기에 있다.
AI는 ‘스타트업의 고통’에 대해 완벽한 에세이를 쓸 수 있다.
하지만 그것은 Reddit 게시글 + 의학 논문 + 자기계발서를 재조합한 것이지,
실재 경험이 아니다.
- AI는 월급날 통장 잔고의 공포를 모른다.
- 믿었던 동료가 떠날 때의 비어버린 사무실을 모른다.
- 제품 실패로 새벽 3시에 혼자 울어본 경험이 없다.
기호 접지(Symbol Grounding) 가 없는 지식은 공허하다.
더 위험한 것은,
이런 ‘경험 없는 지식’을 반복적으로 소비하면
나 역시 내 경험과 단절된다는 점이다.
AI가 정리한 ‘내 프로젝트 회고록’을 읽으면서,
정작 그 순간 내가 무엇을 느꼈는지 기억하지 못하게 된다.
AI가 요약한 ‘팀 회의록’을 보면서,
정작 그 회의에서 오간 미묘한 긴장감을 놓치게 된다.
결과적으로:
AI는 세상과 나 사이에 반투명한 막을 하나 더 깐다.
4. 메타인지의 부재: “틀릴 수 있다”는 것을 모르는 기계
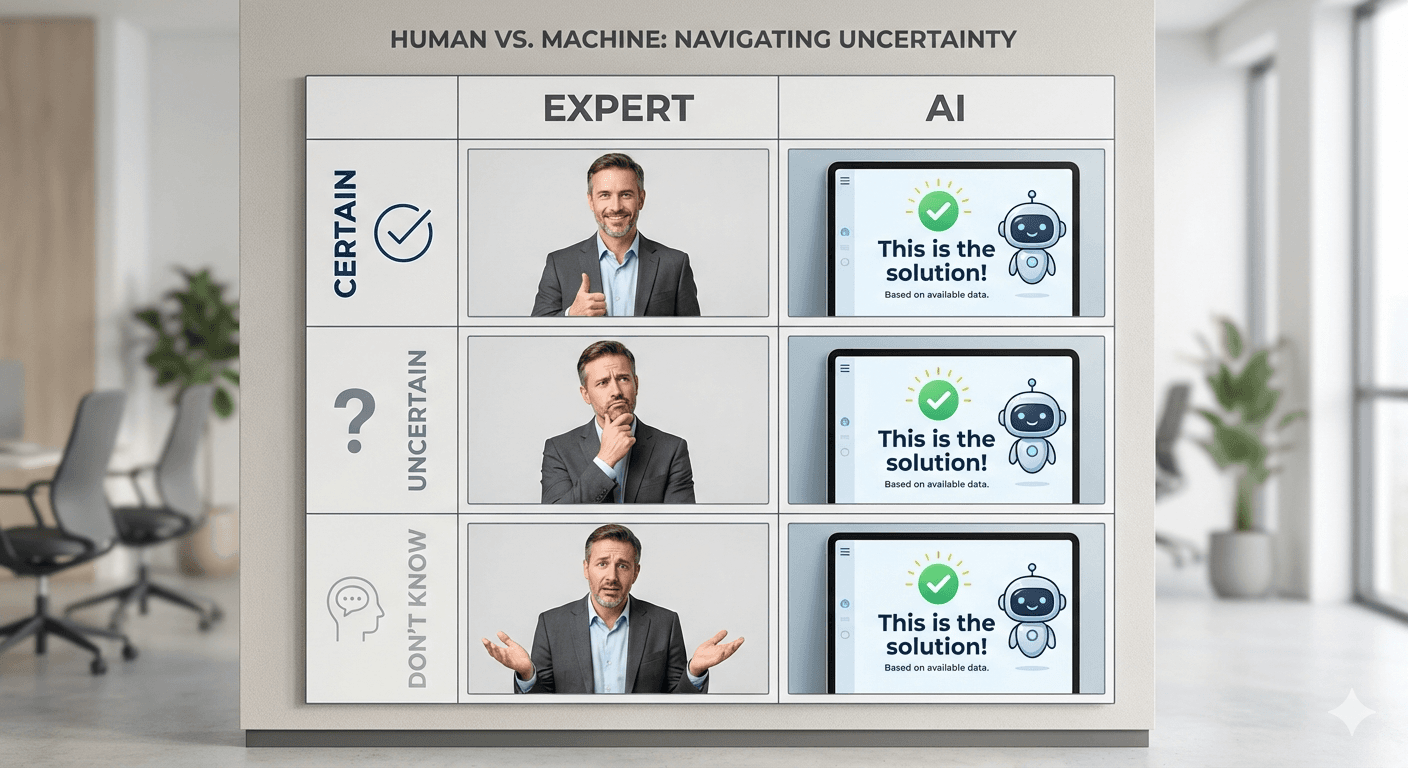
전문가의 가장 중요한 능력 중 하나는 이것이다.
이건 내 전문 분야가 아니라서 확신할 수 없습니다.
이 부분은 ○○ 전문가와 상담이 필요합니다.
AI는 이것을 할 수 없다.
대신 아무것도 모르는 상태에서 가장 그럴듯한 말을 한다.
| 상황 | 진짜 전문가 | AI |
|---|---|---|
| 확실할 때 | “이건 제 전문 분야입니다” | “이렇게 하면 됩니다” |
| 불확실할 때 | “이 부분은 추가 조사가 필요합니다” | “이렇게 하면 됩니다” |
| 모를 때 | “죄송하지만 이건 제 영역이 아닙니다” | “이렇게 하면 됩니다” |
AI는 자기가 맞는지 틀리는지 판단하지 못한다.
그저 확률적으로 “다음에 올 법한 단어”를 이어 붙인다.
결과적으로 우리는
확신에 찬 문장으로 포장된 착시를 소비하게 된다.
더 심각한 문제:
이런 AI의 답변을 반복적으로 소비하면,
나 역시 메타인지를 잃어버린다.
“이건 내가 정말 아는 건가, 아니면 AI가 말한 걸 앵무새처럼 반복하는 건가?”
이 구분이 흐려지기 시작한다.
5. 자동화 편향: 결국 인간이 ‘고무 도장’이 되는 순간

인간의 뇌는 인지적 구두쇠다.
전문가처럼 보이는 시스템을 만나면 스스로 생각하기를 멈춘다.
이것이 바로 자동화 편향(Automation Bias) 이다.
실제 연구:
의사들이 AI 진단 보조 시스템을 사용할 때,
시스템 제안을 과도하게 신뢰해
오히려 단독 판단보다 정확도가 떨어진 사례가 있다.
가장 끔찍한 시나리오:
“나는 리더처럼 보이지만, 실제로는 AI가 만든 결과물에 도장만 찍는 존재.”
- 전략 문서: AI 작성 → 내가 승인
- 인사 평가: AI 초안 → 내가 미세 조정
- 제품 로드맵: AI 제안 → 내가 선택
언뜻 효율적으로 보인다.
하지만 6개월 후:
“왜 이런 결정을 했나요?”
이 질문에 나조차도 대답할 수 없게 된다.
- AI는 책임지지 않고,
- 판단의 흔적은 사라지고,
- 결과는 오롯이 내가 감당한다.
이것이 바로 지적 자살이다.
6. 인지적 부채: 조용히 쌓이는 이자
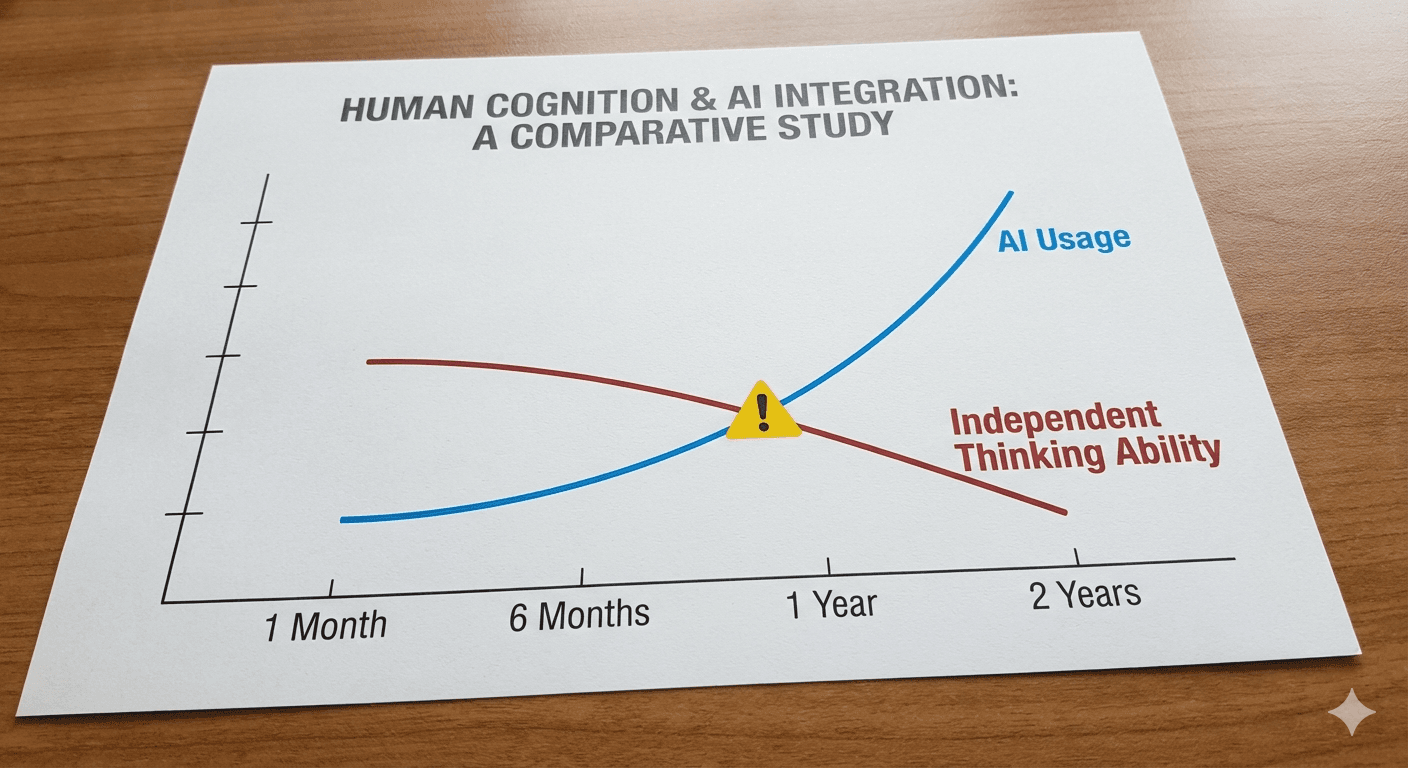
경제학에서 ‘기술 부채(Technical Debt)’라는 개념이 있다.
빠른 개발을 위해 코드 품질을 희생하면,
나중에 더 큰 비용으로 갚아야 한다.
인지적 부채도 똑같이 작동한다.
AI에게 생각을 맡길 때마다:
- 문제 분해 능력이 조금씩 약해진다.
- 논리적 비약을 감지하는 감각이 무뎌진다.
- “이게 정말 맞나?” 의심하는 습관이 사라진다.
처음엔 느끼지 못한다.
AI가 워낙 빠르고 그럴듯하게 답을 주니까.
하지만 1년 후:
- 복잡한 문제 앞에서 멈칫거리게 된다.
- AI 없이는 글을 시작조차 못하게 된다.
- 내 판단에 대한 자신감이 사라진다.
이것은 단순히 ‘의존성’이 아니다.
능력의 퇴행이다.
근육을 쓰지 않으면 위축되듯,
생각하는 근육도 똑같다.
7. 경계 설정: AI와 나 사이의 방화벽
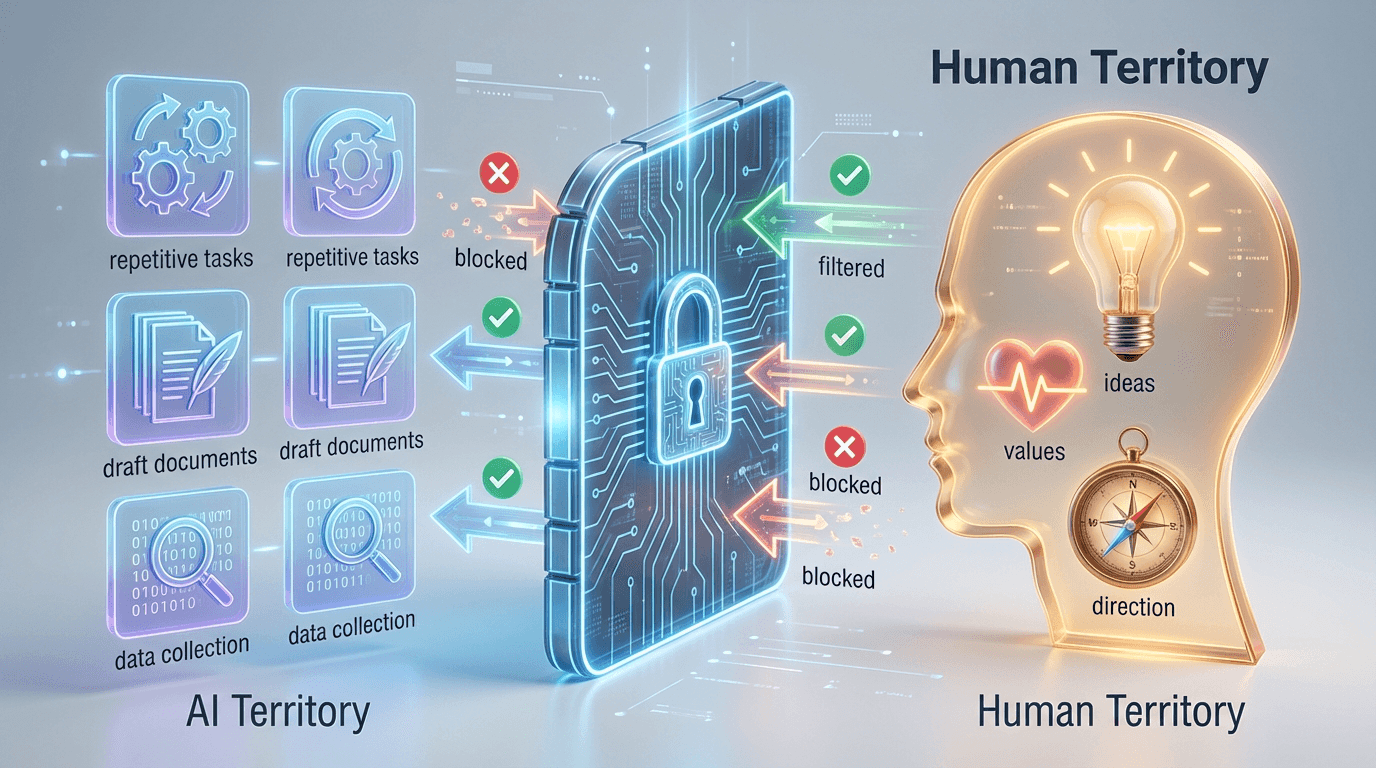
그래서 나는 2025년, AI를 최대한 활용하면서도
시스템적으로 명확한 경계를 긋는다.
AI에게 맡기는 영역 (효율의 영역)
정보 수집 및 정리
“최근 3개월간 경쟁사 동향 정리해줘”초안 작성
“이 아이디어를 바탕으로 초안 작성해줘”반복 작업
“이 패턴으로 10개 더 만들어줘”프로토타입 코드
“이 로직을 구현하는 샘플 코드 작성해줘”
내가 절대 넘기지 않는 영역 (정체성의 영역)
제품의 핵심 철학
“우리는 왜 이걸 만드는가?”타협할 수 없는 기준
“어떤 UX는 절대 받아들일 수 없는가?”조직 문화
“우리 팀은 어떤 가치를 지키는가?”Go/No-Go 의사결정
“이 기능을 출시할 것인가, 말 것인가?”
8. 실천: AI를 증폭기로 쓰되, 주권은 내가 잡는 법
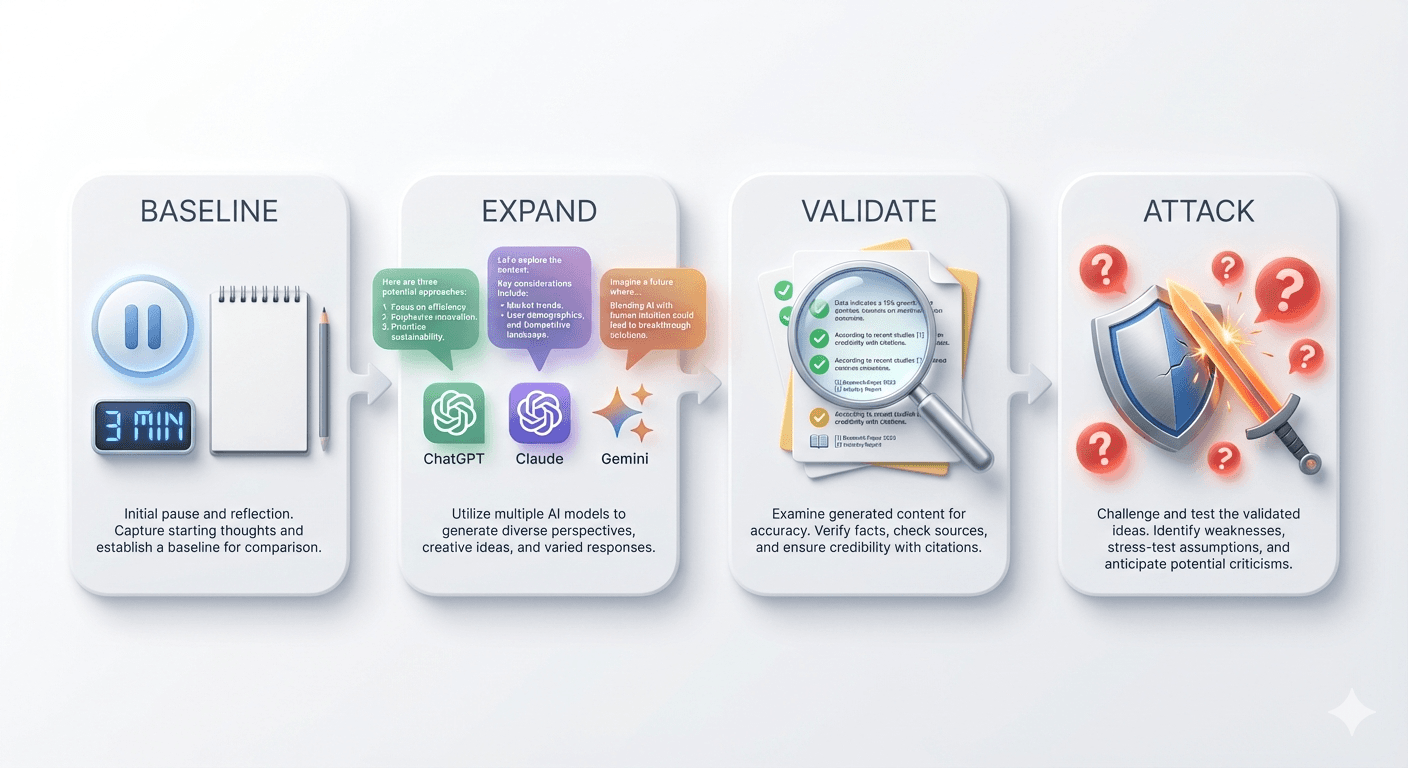
오해하지 말자.
나는 AI를 덜 쓰자는 게 아니다.
오히려 더 전략적으로, 더 깊게 쓰자는 것이다.
AI의 출력물은 엄청난 인지적 자산이다.
문제는 그것을 어떻게 소비하느냐다.
1) The Blind Baseline: 내 현재 이해도 측정
중요한 결정 앞에서,
AI 창을 전부 닫고 메모앱에 먼저 쓴다.
“이 기능을 만들어야 하는 이유는?”
→ 3분 안에 내 언어로 핵심 논리 3개를 적는다.
이건 AI 사용을 줄이려는 게 아니다.
내 현재 이해 수준의 베이스라인을 확보하는 것이다.
막힌다면?
AI에게 물어보기 전에, 내가 뭘 모르는지조차 모른다는 뜻이다.
2) The Multi-AI Expansion: 사고 공간 확장
이제 진짜 AI 활용이 시작된다.
같은 질문을 3개 AI에게 동시에 던진다:
- Gemini 3.0 Pro: “이 기능의 리스크 10가지”
- Claude 4.5: “이 기능이 실패하는 시나리오 5가지”
- ChatGPT 5.1: “이 기능 대신 할 수 있는 대안 7가지”
이건 AI를 의심하는 게 아니다.
세 명의 서로 다른 전문가에게 동시에 자문을 구하는 것이다.
여기서 중요한 것:
- 겹치는 답변 = 높은 확률로 맞다 (합의 영역)
- 한 AI만 말하는 것 = 그 AI의 특수성 or 맹점
- 모두 놓친 것 = 내 도메인 지식이 필요한 영역
이 과정에서 내 사고는 3배로 확장된다.
AI 없이는 절대 도달할 수 없던 영역까지.
3) The Primary Source Validation: 1차 소스 검증
AI가 준 인사이트를 검증 가능한 사실로 변환한다.
- “경쟁사가 이렇게 했다” → 직접 제품 써보고 스크린샷
- “사용자들이 이런 피드백” → Reddit, 앱스토어 리뷰 직접 확인
- “이 기술 스택이 적합” → 공식 문서 + GitHub Issues 확인
AI는 “무엇을 찾아봐야 하는지”를 알려줬다.
이제 나는 그 공간을 직접 걸어다니며 진짜를 찾는다.
4) The Adversarial Test: 내 결정 공격하기
AI 인사이트를 바탕으로, 내 결정을 의도적으로 부순다.
AI들이 제시한 리스크:
- [Gemini] 개발 기간 과소평가
- [Claude] 사용자 학습 곡선
- [ChatGPT] 인프라 비용
내가 추가로 발견한 리스크:
- [1차 소스] 경쟁사 특허 출원
- [도메인 지식] 우리 팀 역량 한계
반론 가능한가? → AI 없이 답할 수 있어야 한다.
5) The Execution Audit: 복기와 학습
3개월 후:
당시 AI 예측:
- Gemini: 리스크 X 발생 예상 → 실제 발생 ✓
- Claude: 리스크 Y 발생 예상 → 발생 안 함 ✗
다음 결정 시:
- Gemini 리스크 분석 더 비중 있게
- Claude 시나리오는 할인해서 듣기
이 메타데이터가 쌓이면,
내 고유의 AI 활용 알고리즘이 생긴다.
결론: 동료로서의 AI, 주인으로서의 나

나는 AI를 사랑한다.
이 도구들은 내 일상을 혁명적으로 바꿨다.
하지만 편리함에는 대가가 있다.
그 대가는 능력의 변화다.
자율주행차가 내 운전을 대신해줄 수는 있다.
하지만 AI가 내 제품의 비전을 대신 꿈꿔줄 수는 없다.
AI가 보고서를 써줄 수는 있다.
하지만 AI가 내 생각의 깊이를 대신 만들어줄 수는 없다.
그 경계를 지키는 것.
화려한 텍스트에 취해 판단을 외주하지 않는 것.
유창함에 속지 않고, 맥락 속에서 다시 깊게 생각하는 것.
AI는 증폭기다
AI를 안 쓰는 사람: 1x 사고력
AI를 맹목적으로 쓰는 사람: 0.3x 사고력
(AI에게 생각을 아웃소싱 → 인지 근육 위축)
AI를 전략적으로 쓰는 사람: 10x 사고력
(AI의 출력을 내 맥락과 충돌시켜 새로운 차원 발견)
유창함은 쉽게 복제된다.
하지만 맥락은 복제할 수 없다.
AI는 내게 엄청난 양의 원료를 준다.
하지만 그것을 내 맥락의 도가니에서 제련하는 건
오롯이 나의 몫이다.
그 제련 과정을 건너뛰는 순간,
나는 AI의 동료가 아니라 AI의 앵무새가 된다.
AI는 내 생산성을 10배로 만들어준다.
하지만 그것이 내 생각을 대체하도록 두지는 않는다.
이것이 특이점을 지나쳐가는 시대 속에서,
내가 지키는 균형의 기술이다.
2025년 11월 23일
Gemini 3.0 Pro, Claude 4.5 Sonnet, ChatGPT 5.1이
동시에 켜진 모니터 앞에서.
하지만 이 글의 모든 문장들은 비록 여러 AI의 도움을 받았을지언정,
AI 창을 닫고 메모앱에 직접 타이핑한 뒤,
내 언어로 다시 조립한 것이다.